Code The City - Day One
Published:
Tags:
HackingCodeTheCity is an event that I was loosely involved in organising that we’re now half way through. It’s all about rapid prototyping of services for the community. While the event is structured as a hackathon, many of those invited were not coders at all and a few times I heard mix ups like confusing Windows with Office and anti-virus software with a firewall. You would think that at an event where the aim is to produce a prototype these people might hold hacks back but it became apparent quickly that the domain knowledge they had could help jumpstart a project. The developers in the teams seemed to code with more confidence knowing they’d got the requirements directly from the person that would be using the system.
Unfortunately, my team did not have any potential end users. I did have a look around the other projects happening but I had basically already decided before attending the event that I was going to work on indexing and making searchable Freedom of Information Act disclosure logs. My team consists of myself and Johnny McKenzie.
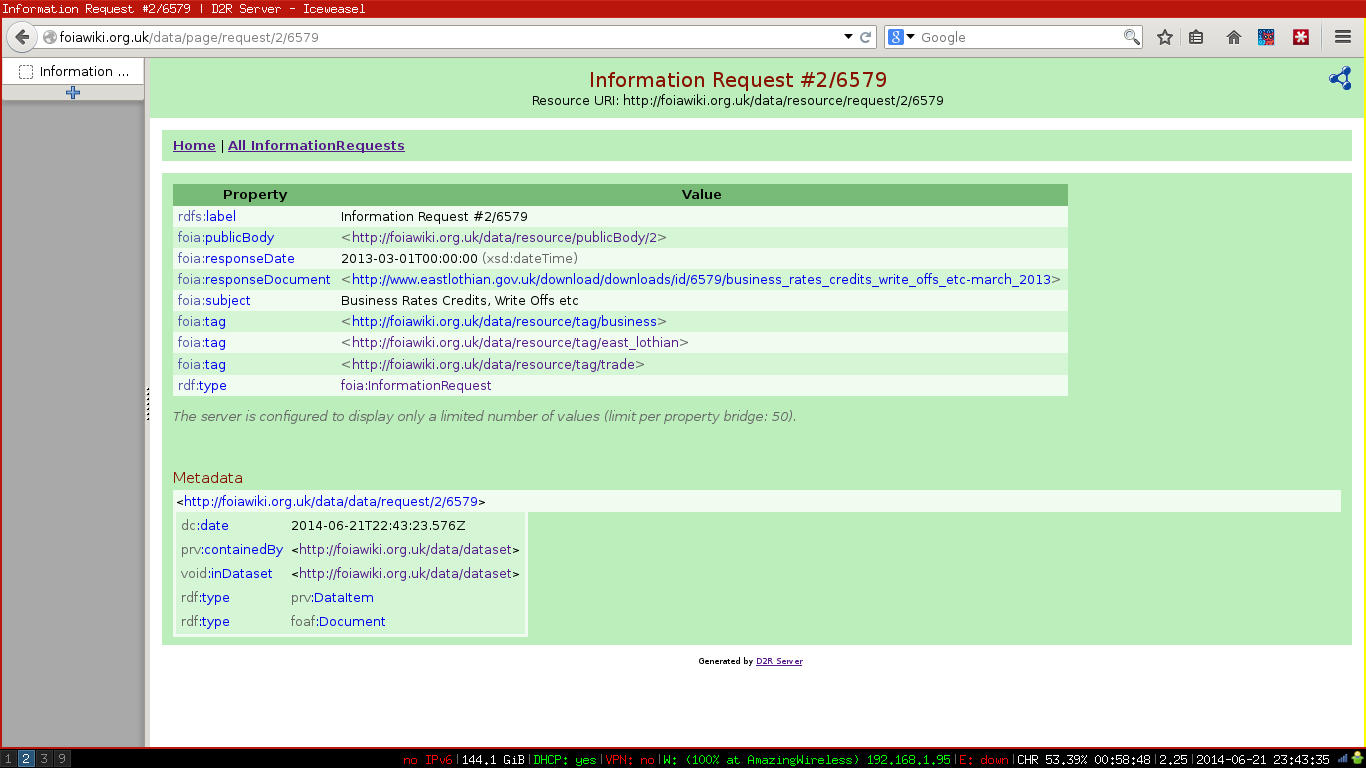
Aberdeen City Council publish a FOI disclosure log but it is not searchable and rather difficult to navigate.
Our first aim was to see what data could easily be extracted from the website and from this we developed a Information Request Ontology that could be used to represent the data. I then set about transforming this into the RDF/XML schema, creating a database schema and a D2RQ mapping while Johnny looked at using Python’s BeautifulSoup to scrape the web pages.
I finished quicker than I anticipated I would and looked at BeautifulSoup too, this time for scraping the East Lothian Council’s log to aggregate into the same database. At the end of day one, we had D2RQ serving linked data and allowing SPARQL queries of the East Lothian disclosures and the code in place to start scraping in the Aberdeen City disclosures.
Screenshot
Depending on how I feel tomorrow, another scraper may be added or maybe an interface for human-friendly search (SPARQL is fine for me, not so much for those that are confusing Windows and Office). An interesting challenge would be to run OCR on the rasterised PDFs to get some bags of words for a better search.