Privacy-preserving monitoring of an anonymity network (FOSDEM 2019)
Published:
Tags:
Security Digital Rights Tor Talk Transcript Free Software Fosdem Events Planet FSFE Planet DebianThis is a transcript of a talk I gave at FOSDEM 2019 in the Monitoring and Observability devroom about the work of Tor Metrics.
Direct links:
Producing this transcript was more work than I had anticipated it would be, and I’ve done this in my free time, so if you find it useful then please do let me know otherwise I probably won’t be doing this again.

I’ll start off by letting you know who I am. Generally this is a different audience for me but I’m hoping that there are some things that we can share here. I work for Tor Project. I work in a team that is currently formed of two people on monitoring the health of the Tor network and performing privacy-preserving measurement of it. Before Tor, I worked on active Internet measurement in an academic environment but I’ve been volunteering with Tor Project since 2015. If you want to contact me afterwards, my email address, or if you want to follow me on the Fediverse there is my WebFinger ID.

So what is Tor? I guess most people have heard of Tor but maybe they don’t know so much about it. Tor is quite a few things, it’s a community of people. We have a paid staff of approximately 47, the number keeps going up but 47 last time I looked. We also have hundereds of volunteer developers that contribute code and we also have relay operators that help to run the Tor network, academics and a lot of people involved organising the community locally. We are registered in the US as a non-profit organisation and the two main things that really come out of Tor Project are the open source software that runs the Tor network and the network itself which is open for anyone to use.
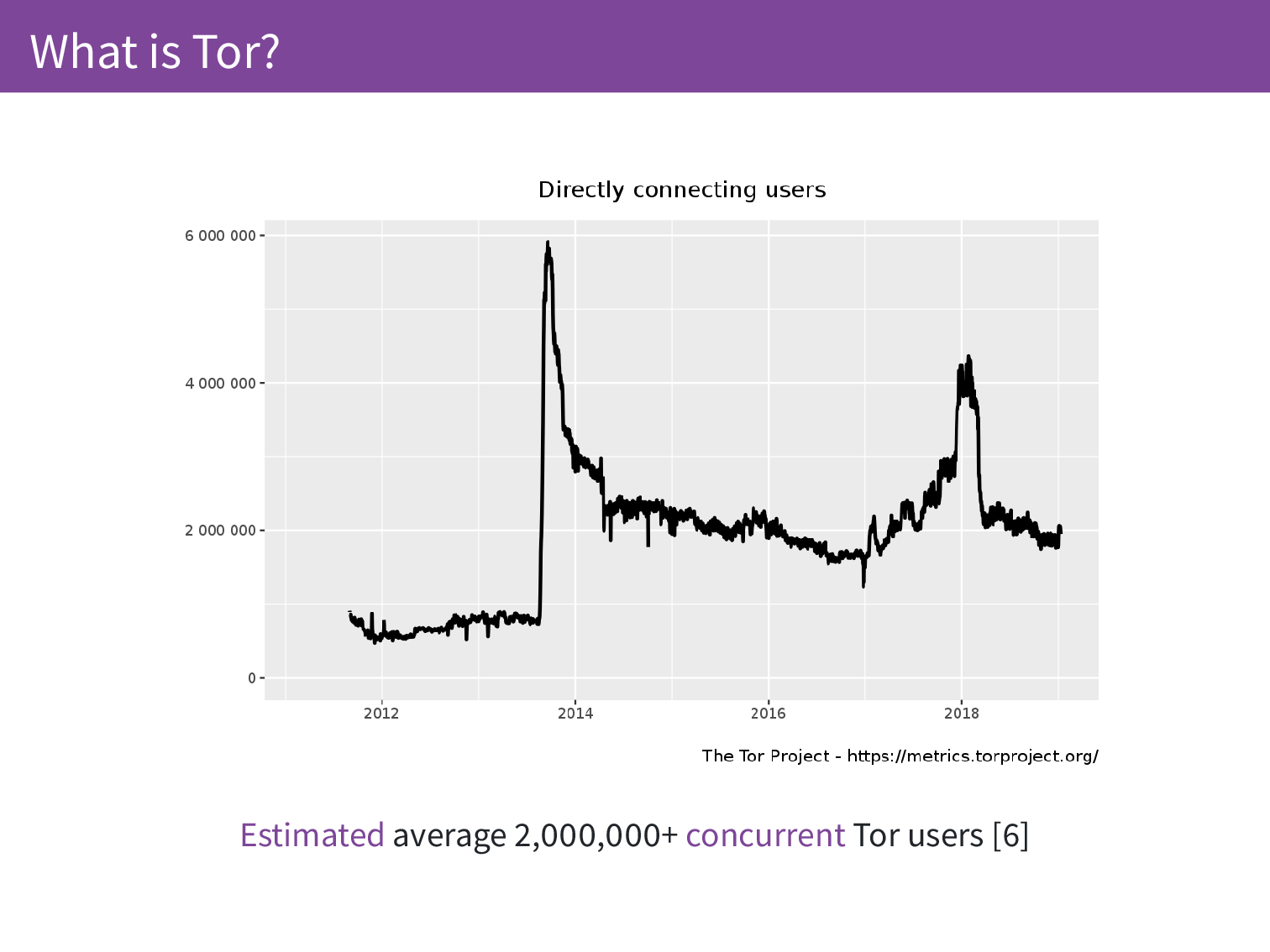
Currently there are an estimated average 2,000,000 users per day. This is estimated and I’ll get to why we don’t have exact numbers.
Most people when they are using Tor will use Tor Browser. This is a bundle of Firefox and a Tor client set up in such a way that it is easy for users to use safely.
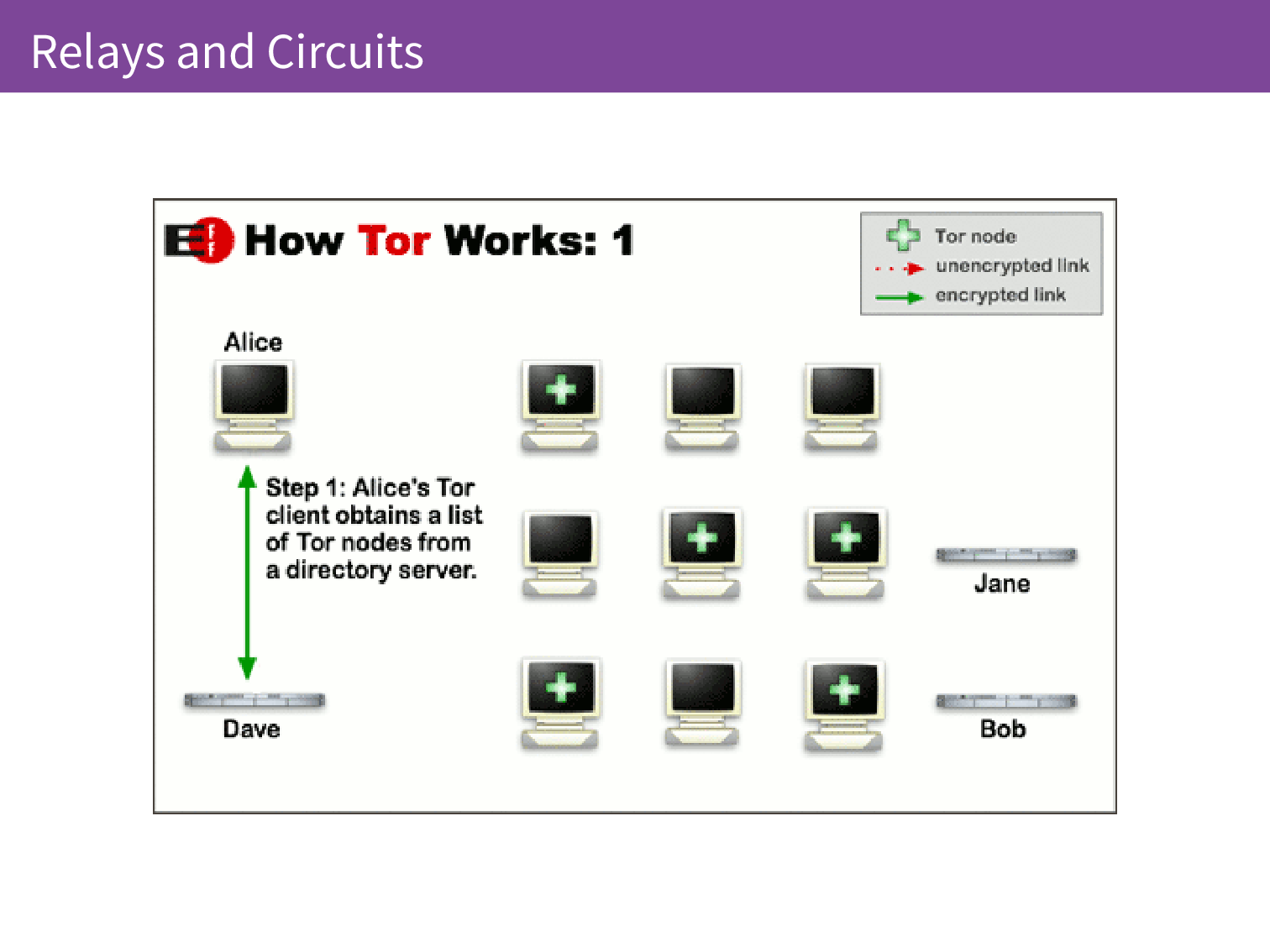
When you are using Tor Browser your traffic is proxied through three relays. With a VPN there is only one server in the middle and that server can see either side. It is knows who you are and where you are going so they can spy on you just as your ISP could before. The first step in setting up a Tor connection is that the client needs to know where all of those relays are so it downloads a list of all the relays from a directory server. We’re going to call that directory server Dave. Our user Alice talks to Dave to get a list of the relays that are available.
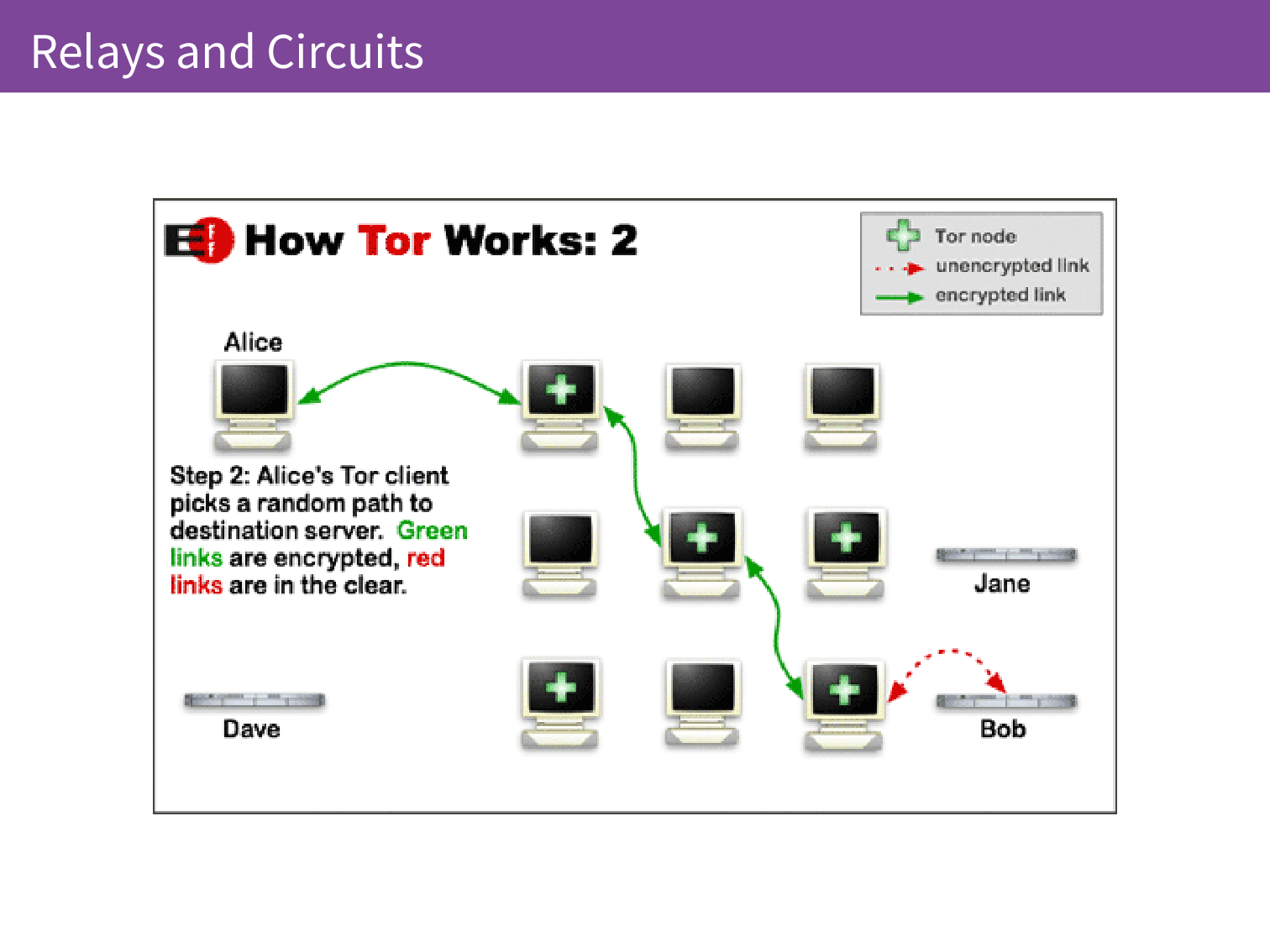
In the second step, the Tor client forms a circuit through the relays and connects finally to the website that Alice would like to talk to, in this case Bob.
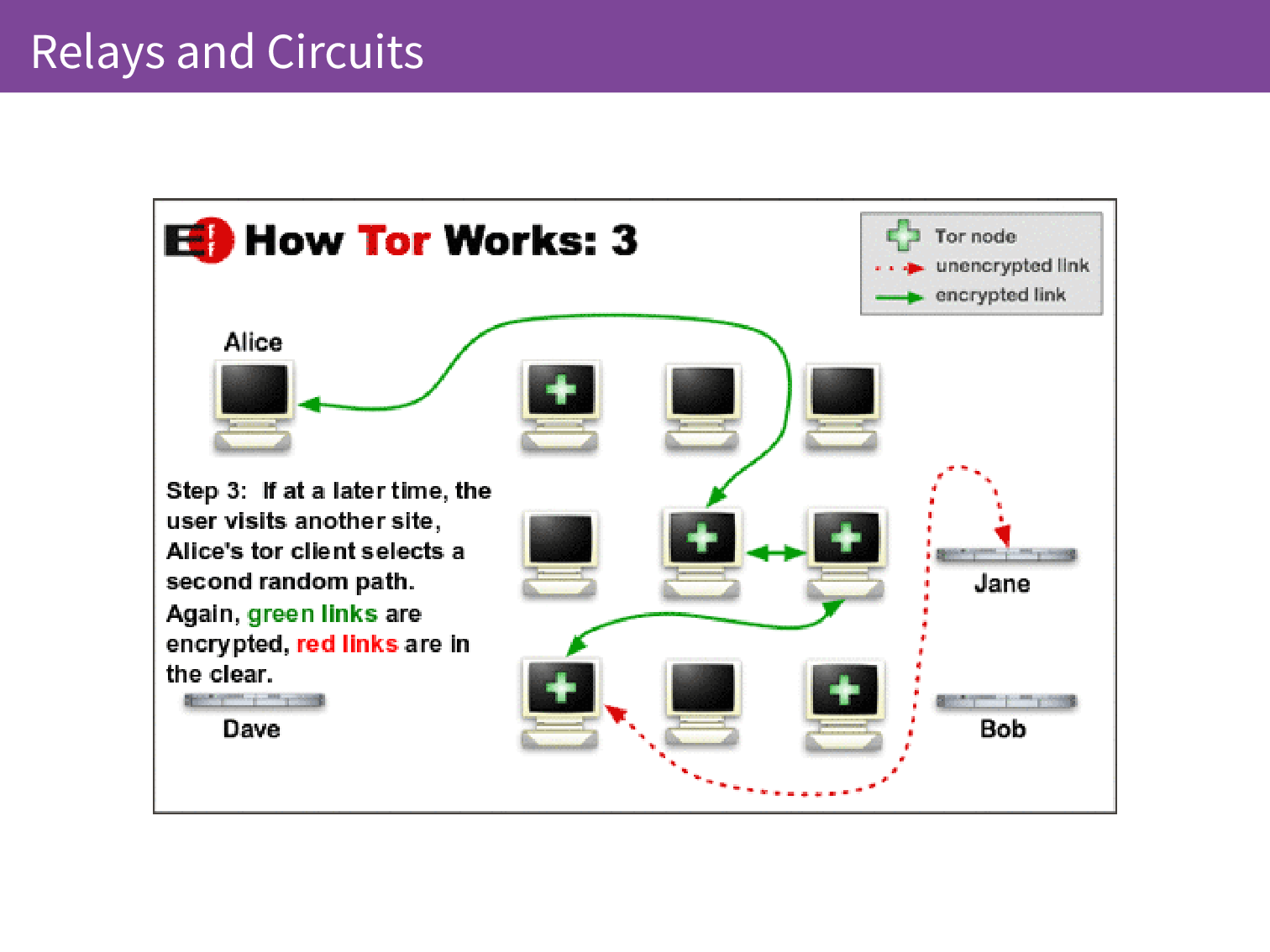
If Alice later decides they want to talk to Jane, they will form a different path through the relays.
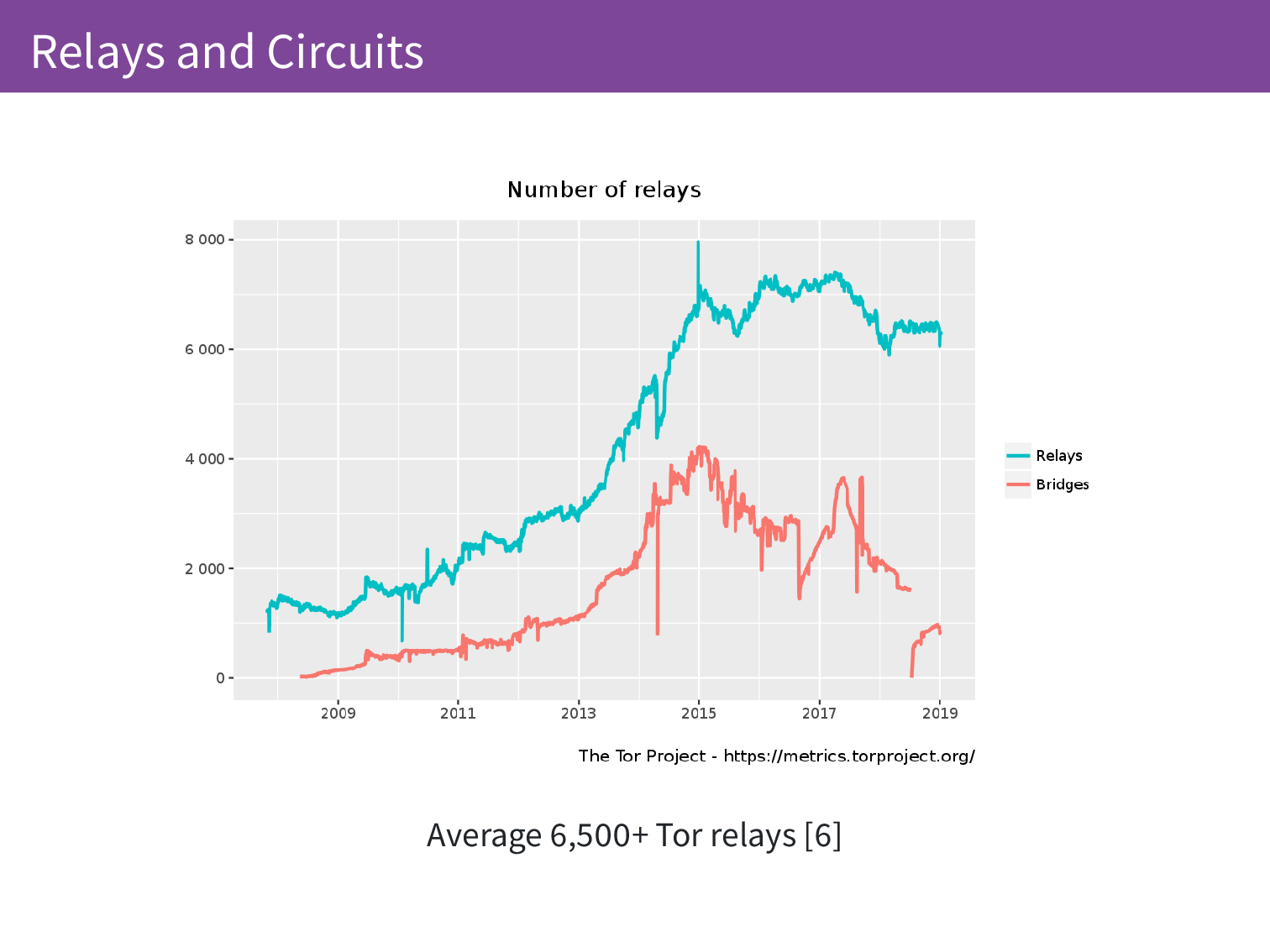
We know a lot about these relays. Because the relays need to be public knowledge for people to be able to use them, we can count them quite well. Over time we can see how many relays there are that are announcing themselves and we also have the bridges which are a seperate topic but these are special purpose relays.
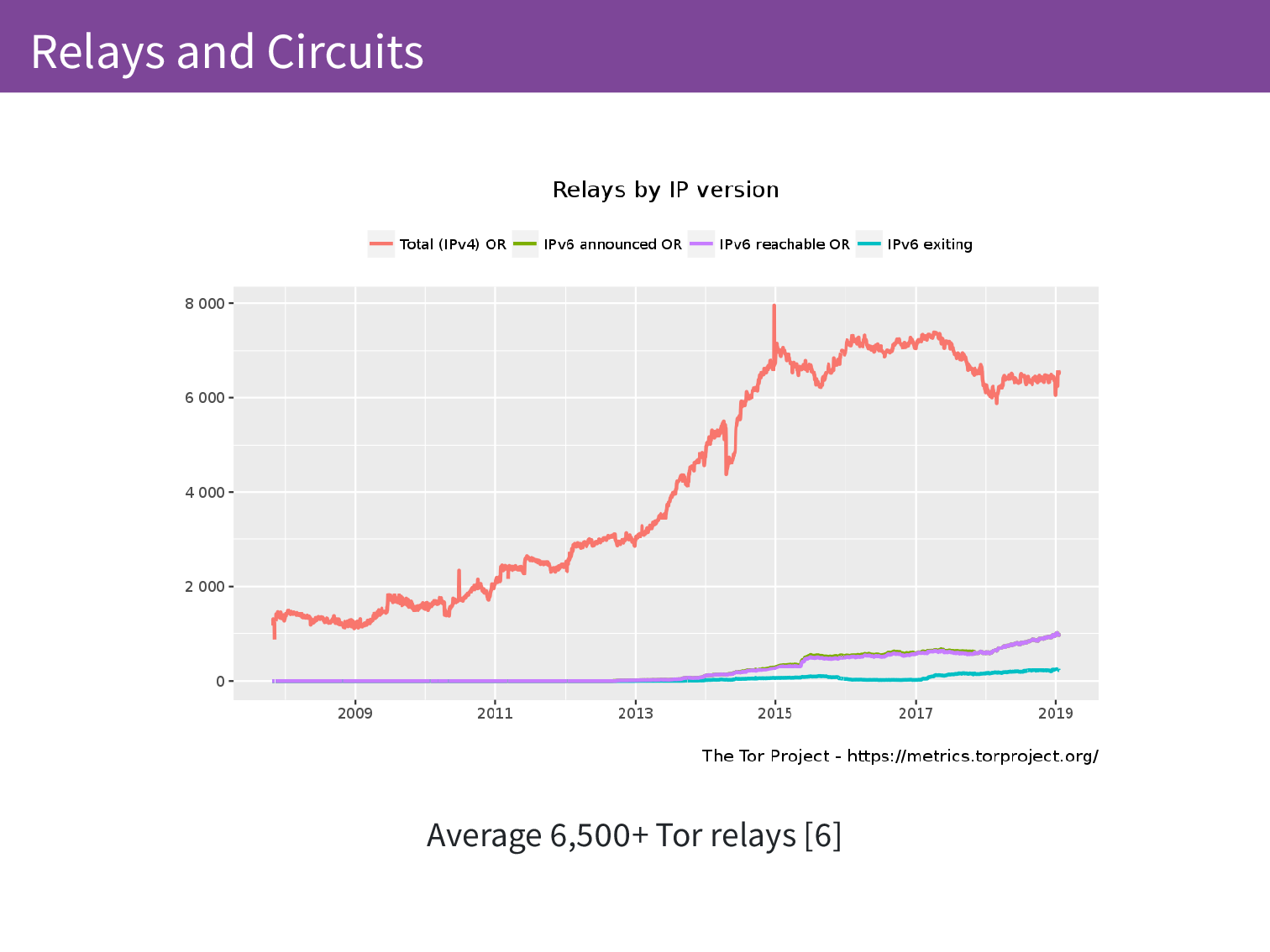
Because we have to connect to the relays we know their IP addresses and we know if they have IPv4 or IPv6 addresses so as we want to get better IPv6 support in the Tor network we can track this and see how the network is evolving.
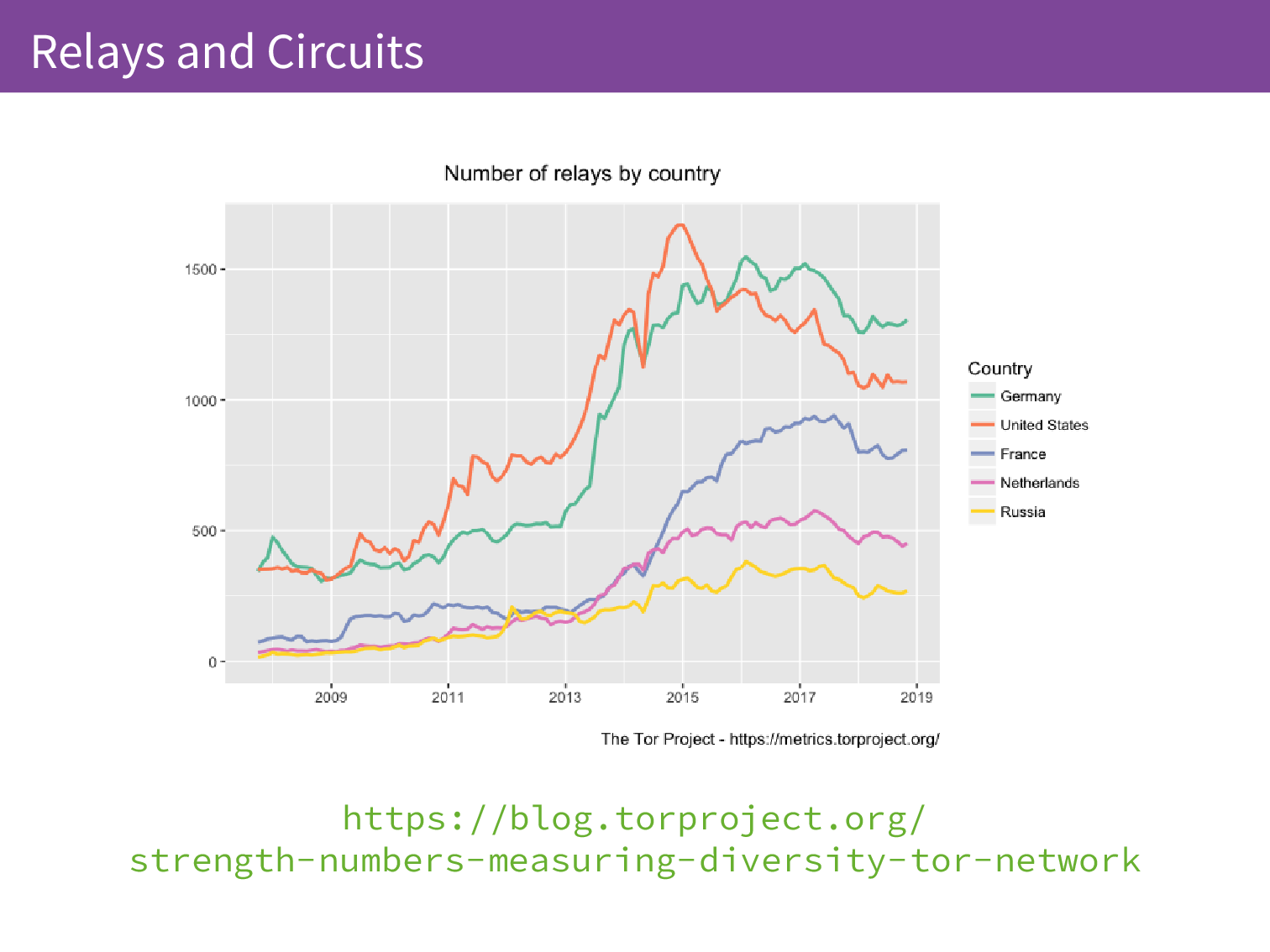
Because we have the IP addresses we can combine those IP addresses with GeoIP databases and that can tell us what country those relays are in with some degree of accuracy. Recently we have written up a blog post about monitoring the diversity of the Tor network. The Tor network is not very useful if all of the relays are in the same datacenter.
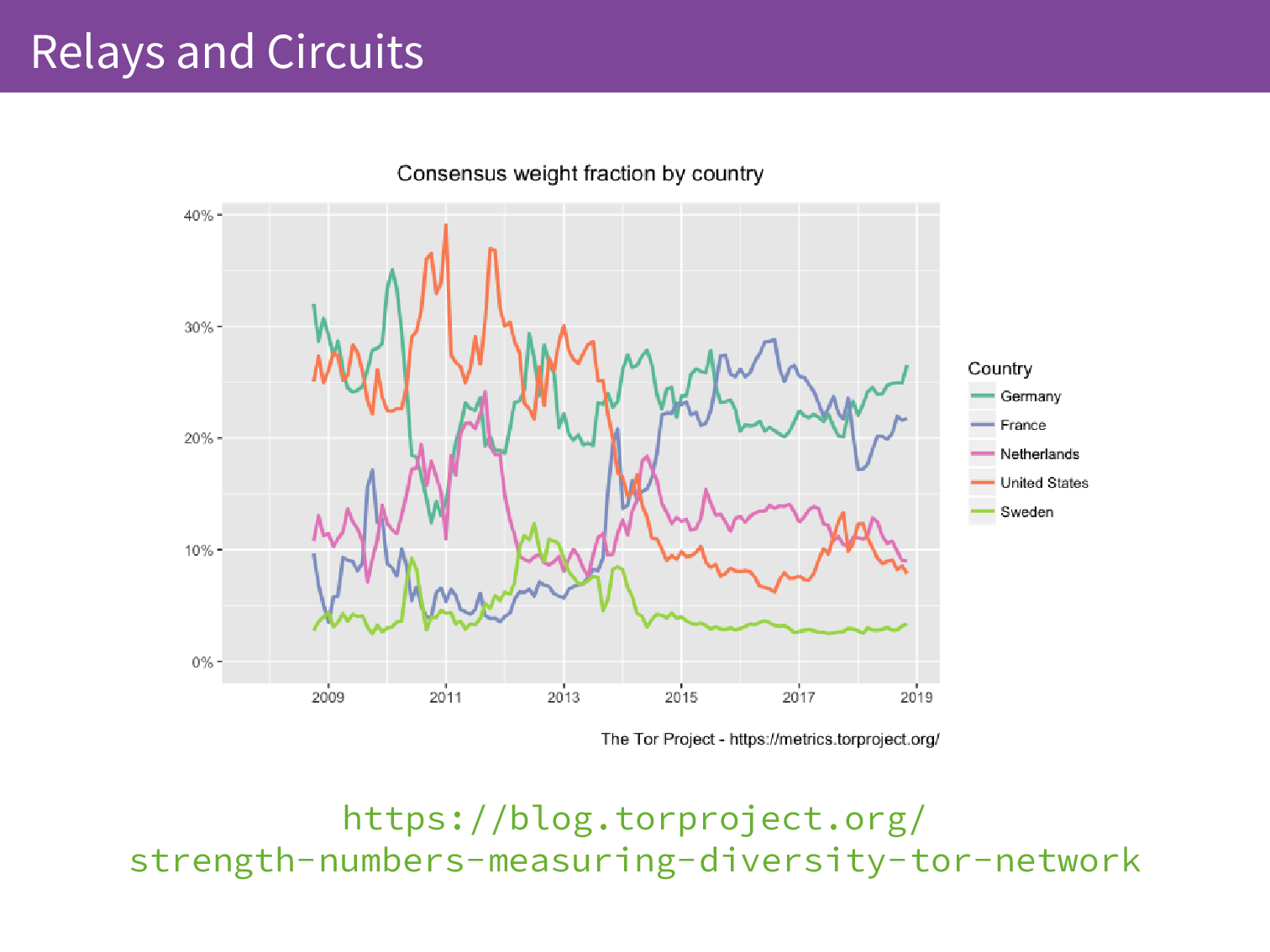
We also perform active measurement of these relays so we really analyse these relays because this is where we put a lot of the trust in the Tor network. It is distributed between multiple relays but if all of the relays are malicious then the network is not very useful. We make sure that we’re monitoring its diversity and the relays come in different sizes so we want to know are the big relays spread out or are there just a lot of small relays inflating the absolute counts of relays in a location.
When we look at these two graphs, we can see that the number of relays in Russia is about 250 at the moment but when we look at the top 5 by the actual bandwidth they contribute to the network they drop off and Sweden takes Russia’s place in the top 5 contributing around 4% of the capacity.

The Tor Metrics team, as I mentioned we are two people, and we care about measuring and analysing things in the Tor network. There are 3 or 4 repetitive contributors and then occasionally people will come along with patches or perform a one-off analysis of our data.

We use this data for lots of different use cases. One of which is detecting censorship so if websites are blocked in a country, people may turn to Tor in order to access those websites. In other cases, Tor itself might be censored and then we see a drop in Tor users and then we also see we a rise in the use of the special purpose bridge relays that can be used to circumvent censorship. We can interpret the data in that way.
We can detect attacks against the network. If we suddenly see a huge rise in the number of relays then we can suspect that OK maybe there is something malicious going on here and we can deal with that. We can evaluate effects on how performance changes when we make changes to the software. We have recently made changes to an internal scheduler and the idea there is to reduce congestion at relays and from our metrics we can say we have a good idea that this is working.
Probably one of the more important aspects is being able to take this data and make the case for a more private and secure Internet, not just from a position of I think we should do this, I think it’s the right thing, but here is data and here is facts that cannot be so easily disputed.

We only handle public non-sensitive data. Each analysis goes through a rigorous review and discussion process before publication.

As you might imagine the goals of privacy and anonymity network doesn’t lend itself to easy data gathering and extensive monitoring of the network. The Research Safety Board if you are interested in doing research on Tor or attempting to collect data through Tor can offer advice on how to do that safely. Often this is used by academics that want to study Tor but also the Metrics Team has used it on occasion where we want to get second opinions on deploying new measurements.

What we try and do is follow three key principles: data minimalisation, source aggregation, and transparency.

The first one of these is quite simple and I think with GDPR probably is something people need to think about more even if you don’t have an anonymity network. Having large amounts of data that you don’t have an active use for is a liability and something to be avoided. Given a dataset and given an infinite amount of time that dataset is going to get leaked. The probability increases as you go along. We want to make sure that we are collecting as little detail as possible to answer the questions that we have.

When we collect data we want to aggregate it as soon as we can to make sure that sensitive data exists for as little time as possible. This means usually in the Tor relays themselves before they even report information back to Tor Metrics. They will be aggregating data and then we will aggregate the aggregates. This can also include adding noise, binning values. All of these things can help to protect the individual.

And then being as transparent as possible about our processes so that our users are not surprised when they find out we are doing something, relay operators are not surprised, and academics have a chance to say whoa that’s not good maybe you should think about this.

The example that I’m going to talk about is counting unique users. Users of the Tor network would not expect that we are storing their IP address or anything like this. They come to Tor because they want the anonymity properties. So the easy way, the traditional web analytics, keep a list of the IP addresses and count up the uniques and then you have an idea of the unique users. You could do this and combine with a GeoIP database and get unique users per country and these things. We can’t do this.

So we measure indirectly and in 2010 we produced a technical report on a number of different ways we could do this.

It comes back to Alice talking to Dave. Because every client needs to have a complete view of the entire Tor network, we know that each client will fetch the directory approximately 10 times a day. By measuring how many directory fetches there are we can get an idea of the number of concurrent users there are of the Tor network.

Relays don’t store IP addresses at all, they count the number of directory requests and then those directory requests are reported to a central location. We don’t know how long an average session is so we can’t say we had so many unique users but we can say concurrently we had so many users on average. We get to see trends but we don’t get the exact number.
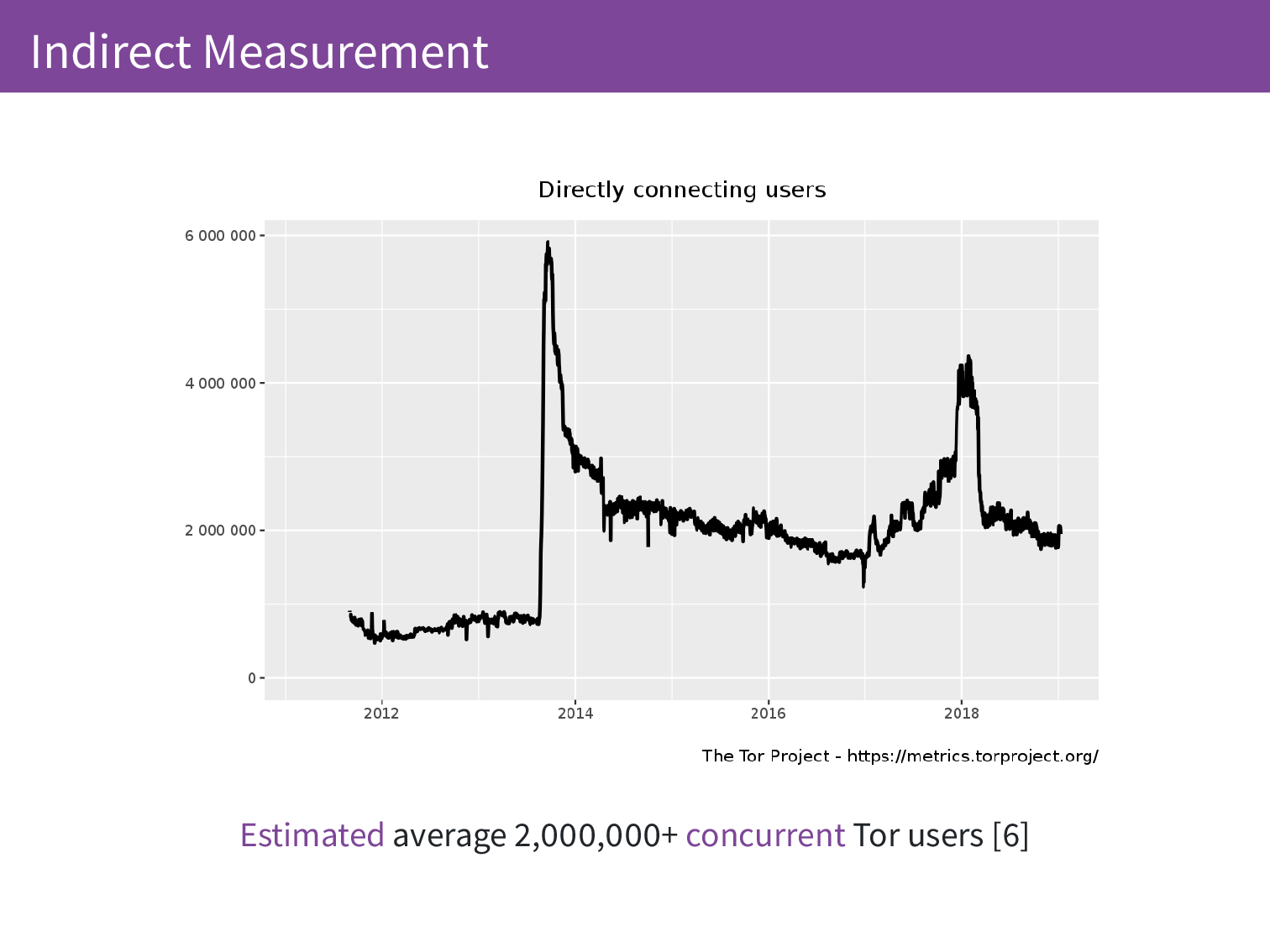
So here is what our graph looks like. At the moment we have the average 2,000,000 concurrent Tor users. The first peak may have been an attempted attack, as with the second peak. Often things happen and we don’t have full context for them but we can see when things are going wrong and we can also see when things are back to normal afterwards.

This is in a class of problems called the count-distinct problem and these are our methods from 2010 but since then there has been other work in this space.

One example is HyperLogLog. I’m not going to explain this in detail but I’m going to give a high-level overview. Imagine you have a bitfield and you initialise all of these bits to zero. You take an IP address, you take a hash of the IP address, and you look for the position of the leftmost one. How many zeros were there at the start of that string? Say it was 3, you set the third bit in your bitfield. At the end you have a series of ones and zeros and you can get from this to an estimate of the total number that there are.
Every time you set a bit there is 50% chance that that bit would be set given the number of distinct items. (And then 50% chance of that 50% for the second bit, and so on…) There is a very complicated proof in the paper that I don’t have time to go through here but this is one example that actually turns out to be quite accurate for counting unique things.
This was designed for very large datasets where you don’t have enough RAM to keep everything in memory. We have a variant on this problem where even keep 2 IP addresses in memory would, for us, be a very large dataset. We can use this to avoid storing even small datasets.

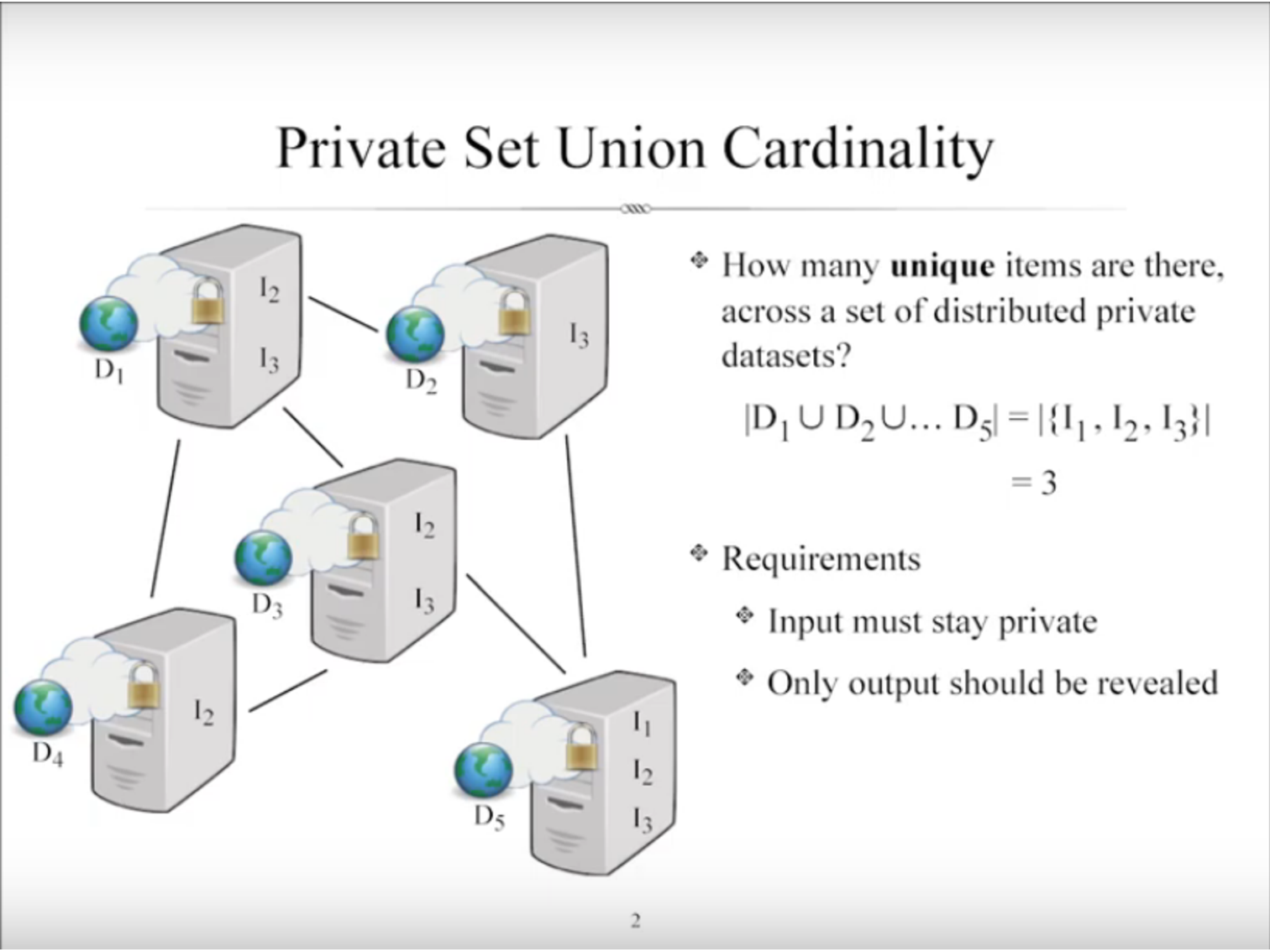
Private Set-Union Cardinality is another example. In this one you can look at distributed databases and find unique counts within those. Unfortunately this currently requires far too much RAM to actually do the computation for us to use this but over time these methods are evolving and should become feasible, hopefully soon.

And then moving on from just count-distinct, the aggregation of counters. We have counters such as how much bandwidth has been used in the Tor network. We want to aggregate these but we don’t want to release the individual relay counts. We are looking at using a method called PrivCount that allows us to get the aggregate total bandwidth used while keeping the individual relay bandwidth counters secret.

And then there are similar schemes to this, RAPPOR and PROCHLO from Google and Prio that Mozilla have written a blog post about are similar technologies. All of the links here in the slides and are in the page on the FOSDEM schedule so don’t worry about writing these down.

Finally, I’m looking at putting together some guidelines for performing safe measurement on the Internet. This is targetted primarily at academics but also if people wanted to apply this to analytics platforms or monitoring of anything that has users and you want to respect those users’ privacy then there could be some techniques in here that are applicable.
Ok. So that’s all I have if there are any questions?
Q: I have a question about how many users have to be honest so that the network stays secure and private, or relays?
A: At the moment when we are collecting statistics we can see – so as I showed earlier the active measurement – we know how much bandwidth a relay can cope with and then we do some load balancing so we have an idea of what fraction of traffic should go to each relay and if one relay is expecting a certain level of traffic and it has wildly different statistics to another relay then we can say that relay is cheating. There isn’t really any incentive to do this and it’s something we can detect quite easily but we are also working on more robust metrics going forward to avoid this being a point where it could be attacked.
Q: A few days ago I heard that with Tor Metrics you are between 2 and 8 million users but you don’t really know in detail what the real numbers are? Can you talk about the variance and which number is more accurate?
A: The 8 million number comes from the PrivCount paper and they did a small study where they looked at unique IP address over a day where we look at concurrent users. There are two different measurements. What we can say is that we know for certain that there are between 2 million and 25 million unique users per day but we’re not sure where in there we fall and 8 million is a reasonable-ish number but also they measured IP addresses and some countries use a lot of NAT so it could be more than 8 million. It’s tricky but we see the trends.
Q: Your presentation actually implies that you are able to collect more private data than you are doing. It says that the only thing preventing you from collecting private user data is the team’s good will and good intentions. Have I got it wrong? Are there any possibilities for the Tor Project team to collect some private user data?
A: Tor Project does not run the relays. We write the code but there individual relay operators that run the relays and if we were to release code that suddenly collecting lots of private data people would realise and they wouldn’t run that code. There is a step between the development and it being deployed. I think that it’s possible other people could write that code and then run those relays but if they started to run enough relays that it looked suspicious then people would ask questions there too, so there is a distributed trust model with the relays.
Q: You talk about privacy preserving monitoring, but also a couple of years ago we learned that the NSA was able to monitor relays and learn which user was connecting to relays so is there also research to make it so Tor users cannot be targetted for using a relay and never being able to be monitored.
A: Yes, there is! There is a lot of research in this area and one of them is through obfuscation techniques where you can make your traffic look like something else. They are called pluggable transports and they can make your traffic look like all sorts of things.